AWS DataZone에서 OpenLineage 기반의 Airflow 데이터 계보 그리기
AWS DataZone에서 OpenLineage 기반의 Airflow 데이터 계보 그리기 | Amazon Web Services
배경 Airflow는 데이터 마트(Data Mart)를 포함한 데이터 파이프라인 구축 및 관리에서 매우 널리 사용되는 도구입니다. 이러한 Airflow에서 데이터 계보가 중요한 이유는 데이터의 출처와 변환 과정을 명확히 추적할 수 있어 데이터의 신뢰성을 보장하고, 문제 발생 시 원인을 빠르게 파악할 수 있기 때문입니다. 또한, 데이터 계보는 규제 준수와 감사 요구사항을 충족시키는 데 도움을 주며, 데이터 파이프라인의 변경이 […]
배경
- Airflow는 Data mart를 포함한 데이터 파이프라인 구축 및 관리에서 널리 사용되는 도구
- 데이터 출처와 변환 과정을 명확히 추적할 수 있어 데이터의 신뢰성을 보장 & 문제 발생 시 원인 빠르게 파악
- 데이터 파이프라인의 변경이 미치는 영향을 사전에 분석 → 위험 최소화
- 데이터 계보는 규제 준수와 감사 요구사항 파악에 도움
데이터 계보를 통해 복잡한 데이터 파이프라인을 효율적으로 운영하며, 데이터 기반 의사결정의 신뢰성과 조직의 데이터 활용 능력을 향상
솔루션 개요
- Amazon DataZone의 데이터 계보 기능을 활용하여 Airflow의 데이터 계보를 그릴 수 있음
- Amazon DataZone 서비스는 DataZone 라이프 사이클 내에서 발생한 게시와 구독 이벤트에 대해서만 데이터 계보가 표현됨 → 그 외에는 직접 작성해야 함
- AWS Lambda를 사용하여 Airflow에 대한 계보를 OpenLineage 표준에 맞게 DataZone에 업데이트 하는 방법을 설명

데이터 생애 주기 관리 서비스
- 표준화된 계보 정보 수집:
- 종단간 계보 시각화:
- 버전 관리:
- 멀티 클라우드 호환:
- 계보 이벤트 캡처: DataZone 도메인 관리자는 OpenLineage API를 사용해 외부 시스템(예: Redshift)에서 발생하는 계보 이벤트를 수동으로 추가할 수 있습니다7.
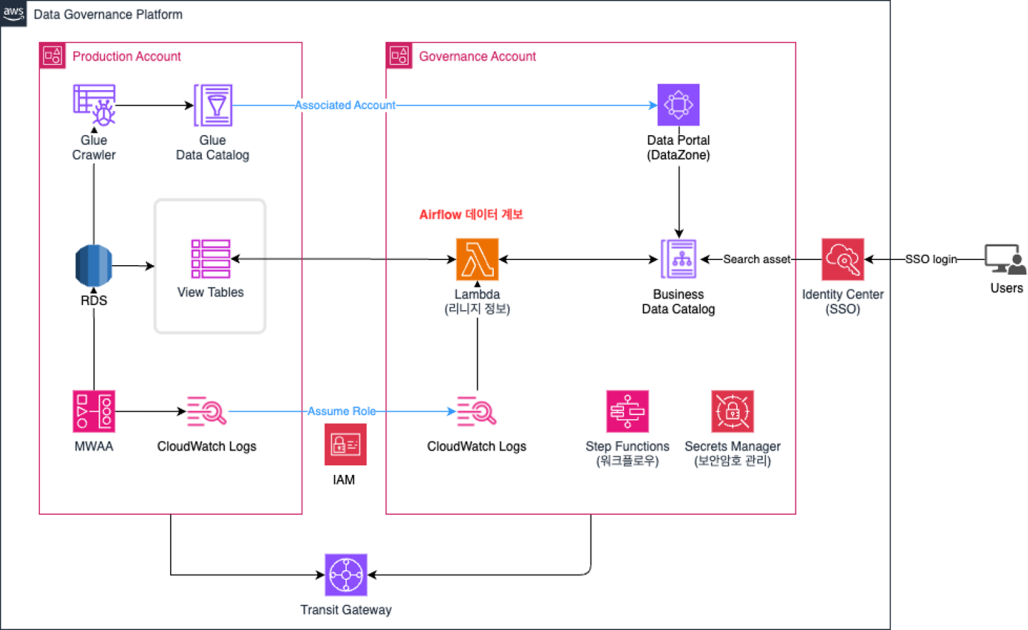
솔루션 아키텍쳐

- Production 계정과 Governance 계정은 Transit Gateway 를 통해 연결되어 네트워크 통신이 가능함
- Production 계정에서 데이터의 저장 및 메타데이터 생성 작업이 이뤄짐
- RDS는 데이터를 저장하고, 사용자의 요청에 따라 View Table을 생성
- AWS Glue Crawler가 RDS 데이터를 스캔하여 메타 데이터를 자동으로 생성, Glue Data Catalog에 저장
- MWAA(Amazon Managed Workflows for Apache Airflow)에서 매일 View Table을 갱신하는 Airflow Job이 배치 형태로 동작
- 동작할 때마다 로그 정보를 CloudWatch에 저장 → 이 정보를 Assume Role을 이용해서 Governance 계정에서 조회
- Governance 계정에서는 Airflow에 대한 데이터 계보 작성과 사용자 접근 제어가 이뤄짐
- Lambda 함수는 매시간 Airflow Job에 대한 로그를 가져옴
- 로그에서 프로시저 함수를 가져오고 함수 이름을 이용해 프로시저 정의 요청 쿼리문을 이용해 Input TB, Output TB 이름을 조회
import os import boto3 import json import re from openlineage_sql import parse from psycopg2.sql import SQL, Identifier, Literal procedure_name = re.search(r'\b([a-zA-Z_]+)\b(?=\()', query).group(1) # 프로시저에 대한 정의를 요청하는 쿼리 요청 sql_query = """ SELECT PROSRC FROM PG_CATALOG.PG_PROC WHERE PRONAME = {}; """ procedure_definition = run_query(config.db_secret_name, SQL(sql_query).format( Literal(procedure_name) ) ) if not procedure_definition: print(f"[ERROR] {procedure_name} 프로시저에 대한 정의가 존재하지 않습니다.") return 'error' else: dml_pattern = r'(DELETE.*?;|INSERT.*?;|UPDATE.*?;|MERGE.*?;)' dml_statements = re.findall(dml_pattern, procedure_definition[0]['prosrc'], re.DOTALL | re.IGNORECASE) sql_query = ''.join(dml_statements) # openlineage_sql을 이용해 파싱한다. meta = parse([sql_query]) in_tables = meta.in_tables out_table = meta.out_tables[0]
- 조회한 정보과 Airflow Job 정보를 조합한 후, 데이터 계보를 Amazon DataZone에 업데이트
결론
- 1.Redis 캐시로 몰려드는 트래픽을 견디다 - 토니모리 공식몰 성능 개선기
- 2.PKCE:OAuth를 더욱더 안전하게 만드는 방법
- 3.AWS DataZone에서 OpenLineage 기반의 Airflow 데이터 계보 그리기
- 4.Chaos Toolkit 을 이용한 카오스 엔지니어링(Chaos Engineering)
- 5.성능 향상을 위한 SQL 작성법
- 6.MongoDB WiredTiger의 파일 구조

NEWPySpark: 대용량 분산 처리 DataFrame 기초
PySpark는 Apache Spark를 Python 환경에서 사용할 수 있게 해주는 API로, 대량의 데이터를 분산 처리할 수 있다. 핵심 구조로는 Driver Node, Worker Node, Cluster Manager가 있으며, RDD와 DataFrame이 주요 데이터 구조이다. 학습 로드맵은 DataFrame 기초 조작, 스파크 최적화 및 고급 기능, 확장 모듈 다루기로 구성된다. Lazy Evaluation, SparkSession 생성, 데이터 불러오기 및 변환, 집계, 조인 등의 기법을 통해 성능을 최적화할 수 있다. 또한, Spark SQL, Structured Streaming, MLlib 등의 확장 모듈을 활용하여 데이터 엔지니어링을 강화할 수 있다.
데이터를 움직이는 힘: 데이터 거버넌스 & 엔지니어링 실전 강의 정리
모두의 연구소 [데이터를 움직이는 힘: 데이터 거버넌스 & 엔지니어링 실전] 강의 수강
MongoDB WiredTiger의 파일 구조
제조 데이터 실무 흐름부터 데이터 거버넌스 프레임워크, 파이프라인 자동화 및 클라우드 ETL 실습까지 데이터 엔지니어링의 핵심 과정을 상세히 정리했습니다. 실무 적용 가이드와 함께 데이터 품질 진단 및 표준화 노하우를 확인해 보세요.
성능 향상을 위한 SQL 작성법
인덱스 구조와 스캔 원리를 기반으로 쿼리 성능을 극대화하는 실무적인 SQL 작성 가이드를 제시합니다. 커버링 인덱스 활용, 정렬 연산 대체, LIMIT 최적화 등 데이터베이스 부하를 줄이는 구체적인 튜닝 기법을 확인해 보세요.